





































































































AI acceleration in laptops refers to the execution of AI algorithms directly on the hardware (instead of in the cloud). In this article, we would like to provide an overview of the basics and future potential and explain which XMG and SCHENKER laptops are already capable of accelerating the execution of AI. The article is centred only on the technical aspects of AI acceleration.
Introduction
Artificial Intelligence in the form of Large Language Models (LLMs) and Diffusion Models has, over recent years, entered the consumer space with widely popular services such as Dall-E, Stable Diffusion, Midjourney and ChatGPT. This has prompted chip manufacturers to optimise parts of their hardware designs to run AI algorithms faster, and with lower power consumption. This article will give an overview over the current state of this eco-system and which XMG & SCHENKER laptops already have AI-acceleration available.
What kind of hardware do I need to get ready for AI?
In the following FAQ article, we show which hardware is required for AI applications:
What is the difference between cloud-based and locally executed AI?
Currently, virtually all consumer and productivity-focused AI applications, such as ChatGPT, operate in the cloud. In this model, when a user queries ChatGPT, the response is generated on OpenAI’s servers, not on the user’s local machine.
However, there are notable exceptions to this cloud-centric approach. Software packages like Stable Diffusion and GPT4All (as in: “GPT for all”) mark a shift toward local AI acceleration in laptops. These open-source models are installed and run directly on a user’s computer. Initially, executing these models locally required robust GPUs with substantial video memory. However, recent and upcoming CPU platforms are making local execution more accessible with built-in AI accelerators called “NPUs” – neural processing units.
What are the advantages of locally executed AI?
Looking ahead, local AI accelerators are expected to enable increasingly narrower, specialised use-cases. Whether to generate content, augment existing workflows or enhancing user experiences, executing these tasks on local hardware offers several advantages:
- Reduced latency: local execution eliminates the delays inherent in client-server communication, allowing for quicker responses. This may enable real-time applications that require an immediate response, such as video conferencing, music production and gaming.
- Internet connection independence: performance becomes less dependent on the quality of the user’s internet connection.
- Scalability for developers: by leveraging local hardware, developers, particularly those from smaller, independent, or non-profit backgrounds, can scale their applications without the need for extensive server infrastructure. This is particularly advantageous for those who may not have the resources to maintain a global server network.
- Security and privacy: running AI algorithms locally enhances security as it minimises the need to transmit potentially sensitive data to third-party servers. For services like ChatGPT, which may retain user input for model training, executing locally helps mitigate privacy concerns associated with uploading personal or confidential data.
Upcoming use-cases for local AI might include:
- User interfaces: local AI can power more intuitive and responsive elements, like advanced voice recognition and real-time language translation, adapting interface configurations to user preferences.
- Gaming: enhancing realism in gaming through AI, such as adaptive AI opponents or natural language interaction with non-player characters (NPCs) in role-playing games or sims.
- Generative AI and personal assistants: universal chatbots and image creation tools already exist but may see wider deployment once they can be used locally, without the underlying privacy concerns of online subscriptions.
AI acceleration in laptops: NPUs, GPUs, Tensor Cores etc.
AI or LLMs can be executed on any CPU (central processing unit). But like 3D rendering, doing it on the CPU cores is relatively slow, even if the CPU is run at maximum power.
There are number of specialised hardware designs that can do the same job much faster and more efficiently.
Efficiency is defined in “performance per watt”, i.e. how much electrical energy a system needs to perform a certain task. In the realm of mobile hardware such as phones and laptops, an increase in efficiency translates directly into an increase in battery life.
Here is a list of the most common accelerators:
| Term | Spelled out | Description |
| GNA | Gaussian & Neural Accelerator | Available since Intel Core 10th Gen, GNA is specialised on audio and video processing and was mostly used for active noise cancellation from webcam and microphone signals. |
| NPU, VPU, IPU | Neural / Versatile / Intelligent Processor Unit | These are modern, dedicated AI acceleration engines that are built into modern and next-gen CPU platforms. Unlike Intel GNA, these processing units are more generalised towards LLMs instead of being optimised for audio/video enhancement. Different vendors currently use different acronyms. Summarised with the term “NPU” within the scope of this article. |
| GPU | Graphics Processing Units (Graphics Cards) | These were originally designed to accelerate 3D graphics, but they are also very capable of accelerating AI. While they may not be quite as efficient as NPUs, they are extremely powerful, ubiquitous (available in large numbers, everywhere) and have a long development history, leading to very mature designs and stable drivers and development tools. GPUs are available as iGPU (integrated into CPUs) and dGPU (dedicated, stand-alone. NVIDIA GPUs are especially popular among AI developers due to their well-documented CUDA programming interface. |
| – | Tensor Cores | Tensor Cores are a sub-section of GPU hardware design, first introduced by NVIDIA in 2019. They are designed to accelerate AI workloads. On the client-side, they are used for gaming (upscaling, frame generation) and server-side (in data centres) for training and running the larger AI models that power services such as ChatGPT. Essentially, Tensor Cores are like NPUs – but since they are only available in dedicated GPUs (dGPUs), they are listed as a separate item. For laptops, it is generally better for battery life if you can avoid activating your dGPU for small, recurring, daily workloads. |
| TPU | Tensor Processing Units | A special kind of NPU, developed by Google. TPUs have their own memory directly on the chip, while NPUs still follow the traditional “von Neumann” architecture in which processing units and memory are kept separate. TPUs are considered to be more power-efficient than NPUs, while having lower peak performance. TPUs are currently only available in Google’s cloud architecture and some recent Google phones. |
| AVX512 | Advanced Vector Extensions (512-bit) | These are an extension to the x86 CPU architecture, available in some, but not all modern CPUs. Less efficient than NPUs and GPUs, but more efficient than using the normal x86 CPU cores. Might serve as a fallback in systems where NPUs or GPUs are not available. |
Further information on the technological history can be found in the AI accelerator article on Wikipedia.
Conclusion: for consumer hardware, neural processing units (NPUs) that reside within the CPU package are seemingly the most flexible solution, while also being quite power efficient. An example for the flexibility is the fact that NPUs benefit from system memory upgrades (can process larger amounts of data), while TPUs are limited to their own built-in memory. This makes NPUs quite similar to iGPUs, which also benefit from faster, bigger RAM. Being able to benefit from AI acceleration without the need of a powerful (expensive, power-hungry) GPU will make local AI more accessible on a wider array of portable devices.
NPUs may become the norm in next-gen CPU platforms
We can already see NPUs being rolled out into current mainstream hardware:
- AMD Ryzen 7040 series (codenamed “Phoenix”) includes an NPU from AMD, marketed under the umbrella term “Ryzen AI”
- Intel Core Ultra series (codenamed “Meteor Lake”) includes an NPU from Intel, a powerful step up from the previous “GNA” (Gaussian & Neural Accelerator) that become part of the Intel Core platform since 10th Generation (Ice Lake).
- AMD has already announced AMD Ryzen 8040 series (codenamed “Hawk Point”) which is supposed to increase the performance of the NPU that was introduced in “Phoenix”.
These product segments are aimed at mobile computing (laptops), where power efficiency and battery life are vital to the user experience. These mobile CPU platforms will usually also become available in Mini-PCs and other ‘thin client’ solutions.
Desktop platforms have not been announced with NPUs yet – but this may only a matter of time. At the moment, desktop CPUs in high-end PCs are usually paired with a powerful, dedicated GPU, so there is already plenty of AI-capable hardware available in desktops.
NPU in AMD Ryzen 7040 series (AMD Ryzen AI)
Introduction to Ryzen AI
AMD began to use the term “Ryzen AI” with the launch of AMD Ryzen 7040 series. It describes not only the NPU residing inside the CPU, but also a set of development tools, drivers and software applications that go with it. The footnotes on the Ryzen AI website states:
“Ryzen AI is defined as the combination of a dedicated AI engine, AMD Radeon graphics engine, and Ryzen processor cores that enable AI capabilities.”
This statement alludes to the fact that AMD may use both the NPU and the iGPU when accelerating AI workloads. The footnote further reads:
“OEM and ISV enablement is required, and certain AI features may not yet be optimised for Ryzen AI processors.”
Let us examinate that second statement:
- “OEM enablement” describes that AMD Ryzen AI may not be available on every system with AMD Ryzen 7040. Instead, the OEM (the manufacturer of the complete system) needs to “enable” the functionality. AMD does not clarify, what exactly this enablement entails.
- “ISV enablement”: ISV stands for “integrated software vendor”. This statement probably describes the obvious: software developers will need to use specific APIs in order to offload their AI workloads to the NPU or iGPU. It will not just magically accelerate pre-existing software out of the box.
The requirement of “OEM enablement” has caused some confusion among end-users.
- If you buy a Ryzen 7040 system today, how do you know if Ryzen AI is already enabled?
- If an existing Ryzen 7040 system does not have Ryzen AI enabled yet, is it possible that it will get enabled later?
To clear up these questions, we would like to publicly disclose what exactly is behind this “OEM enablement” and how to find out if your system already has AMD Ryzen AI enabled.
Hardware and drivers: enabling the IPU in Ryzen AI
In marketing, AMD is using the term “AI engine” to describe the AI acceleration in Laptops in their Ryzen platform. In developer specifications and drivers, they use the term “IPU” (Intelligent Processor Unit). For the sake of consistency, we will use the term “IPU” in this paragraph synonymously with “NPU” or “AI engine”.
First, the IPU must be enabled in BIOS. Whether it is enabled or not, depends on the individual OEM.
The necessary BIOS option is part of AMD’s reference code but may not necessarily be exposed to the end-user in all compatible systems. If you can find an option for “IPU” or “IPU DPM” in your BIOS setup, enable it. If you cannot find the option, it may still be enabled anyway.
For XMG and SCHENKER laptops with AMD Ryzen 7040 series and beyond, we are providing an option to enable and disable the IPU in all compatible models via a BIOS Setup option. Please check the paragraph “Which XMG and SCHENKER laptops already have AI acceleration enabled?” further down below for current status.
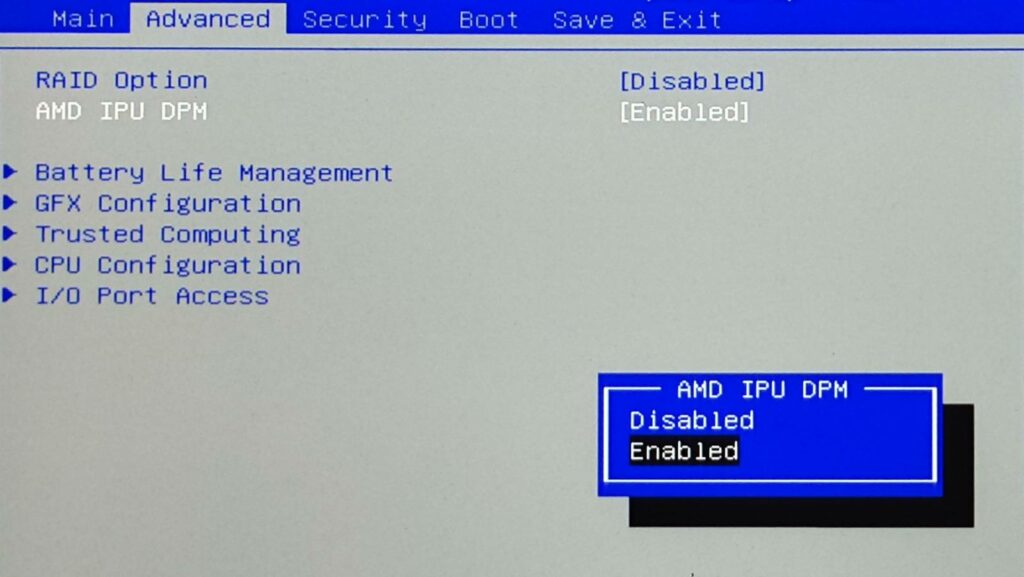
The IPU will be enabled by default, but users can disable it as to their own preference.
Once enabled, the IPU is provided to the operating system as an additional device. You can then find it in Windows Device Manager under “System devices” with the Hardware ID “VEN_1022&DEV_1502”. See screenshot:
[Screenshot of Device Manager option to be added later]
If you cannot find this device, the IPU is likely not enabled in BIOS.
The driver for this IPU device is part of the AMD Graphics driver package, also known as “AMD Software: Adrenalin Edition”. You may need to install the OEM driver first, before installing the latest Graphics driver from AMD. The technical backgrounds of this two-step approach are detailed in this thread:
Integration into operating system
The integration of AMD Ryzen AI and other NPU-accelerated AI workloads is still in its infancy. The only use-case known to us so far is labelled “Windows Studio Effects”, as described in this article:
These effects include standard video conferencing features such as “background blur” (for webcam) and “voice focus” (mutes background noises on the microphone), but also includes the more novel feature “eye contact”, which makes the webcam video feed look as if the user is actually looking into the webcam, instead of looking at the screen below.
It seems that these features are only selectively made available by Microsoft (here acting as ISV – integrated software vendor) to participating OEMs. Besides the neural processing unit (NPU), “Windows Studio Effects” seems to require specific, validated webcams and microphones in order for Microsoft to guarantee the quality of the user experience. As Microsoft’s enablement process currently seems to be only designed for large, multinational OEMs, we currently do not participate. Thus, “Windows Studio Effects” are not available on XMG and SCHENKER laptops, even if an NPU is present and enabled.
Whether or not future potential OS integration in Microsoft Windows will also follow such a selective OEM-enablement strategy, is currently unknown.
Software support for developers
AMD is providing relevant information for developers on their own website and on github:
- Ryzen AI Software [amd.com]
- Ryzen AI Software [github.com]
Reminder: our hardware, firmware and driver are ready for local AI acceleration
As outlined above, AI acceleration in laptops depends on a full pipeline from hardware over firmware, driver and finally to software. Some software vendors (e.g. Microsoft) may currently be selective on which devices they enable their AI use-cases. But this may change soon once NPU adoptions has become more wide-spread and once more third-party developers joined this eco-system to develop applications that leverage the NPUs in recent and next-gen CPU platforms.
Support for Linux
Official Linux drivers for AMD Ryzen AI have become available at the end of January 2024. See this article for details.
NPU in Intel Core Ultra Series (Intel AI Boost)
Intel has launched the new Intel Core Ultra Series in December 2023. With this generation, Intel integrates a powerful NPU into the CPU platform, side-by-side with an also quite strong iGPU. While previous Intel Core i-generations only had the older “GNA” (Gaussian & Neural Accelerator), the new Intel Core Ultra series will feature both NPU and GNA. Intel provides relevant drivers for both Windows and Linux.
Official documentation can be found here:
- Intel Core Ultra Processors Family [intel.com]
- The AI PC from Intel [intel.com]
- Intel NPU Driver – Release Notes [intel.com]
Intel currently speaks of “more than 300 AI-accelerated ISV features”. This describes solutions implemented by third-party providers, many of which are currently still related to Content Creation. These are not 300 different software packages, but the individual features (e.g. effects, filters) within those programs. Intel gives some examples on the page “The AI PC”.
Our enablement strategy for AI in Intel Core Ultra series
Our enablement for the NPU in Meteor Lake will be similar to the one in AMD:
- We will expose the option to enable the NPU via BIOS setup.
- The option will be enabled by default.
- The NPU driver will be provided by us.
- The device will be labelled “Intel AI Boost” in Device Manager.
It will then depend on software vendors, whether or not they choose to use the NPU for their user experiences.
We expect to launch laptops with Meteor Lake in Q2 2024 (see roadmap update). Before that, we will attempt to apply for “Windows Studio Effects”-enablement with Microsoft. However, it is currently unknown whether this application will succeed. Regardless of Microsoft’s OS integration, the NPU in Intel Core Ultra series will be available for software developers and third party apps in XMG and SCHENKER laptops.
Which XMG and SCHENKER laptops already have NPUs built into their CPU platforms?
First, we need to remind again that every laptop with a NVIDIA GeForce RTX or any other modern, dedicated graphics card is very capable of running AI workloads locally. The complexity of these workloads is only limited by the amount of video memory (VRAM) and the choice of AI model. However, this article focuses more on the smaller, more energy-efficient NPU components that are directly integrated into recent and upcoming CPUs.
We have worked with our ODM partners to build BIOS updates that allow end-users to enable and disable the NPU component in their CPU platform. Currently, this applies to the following models:
| Series | CPU platform | Status |
| SCHENKER VIA 14 Pro | AMD Ryzen 7040 Series | Released |
| XMG APEX (L23) | AMD Ryzen 7040 Series | Released |
| XMG CORE (L23) | AMD Ryzen 7040 Series | Released |
Please note:
- Models that are not in this list do not have NPU components in their CPU platform.
- Usage of CPU, iGPU, dGPU or AVX512 (if available) for local AI processing is independent from NPU-enablement. In other words: laptop models without NPU can still process AI workloads – they just have to use other components for acceleration.
AI computing performance comparison
We would like to maintain a brand-agnostic performance comparison between the AI-acceleration capabilities of current CPU platforms. As a starter, we use the metric “TOPS” (TeraOPS, understood as “trillion operations per second”) as a performance indicator for ai acceleration in laptops. Later, we may also add industry-standard benchmark scores.
For a preview, please refer to this link:
- CPU Platform AI Acceleration Comparison [Google Sheets]
The table is work in progress. The values are currently based on publicly available information (specifications provided by CPU vendors and marketing materials), not on any of our own testing. That is why a lot of fields (such as iGPU comparison in AI) is still left “tba”.
Rules of thumb:
- If an iGPU is stronger in gaming or 3D rendering (compared to another iGPU), it is probably also stronger in AI.
- A proper dGPU will always have more raw performance than a (CPU-integrated) NPU. But limited memory capacity of dGPUs can be a concern. More on this in the next paragraph.
How much memory do I need for local AI acceleration in laptops? And how does this affect my choice between NPU and GPU?
Preliminary answer
We would propose the following recommendation: a future-proof system that is built with local AI workloads in mind should have at least 32 GB of system memory installed.
To put this recommendation into context, we would like to further expand on the differences between NPUs and GPUs with relation to memory capacity and memory access.
Size of current and future AI models
When comparing the raw performance (as measured in TOPS) of AI accelerators, one must also take into account the memory requirements of real-world AI applications.
AI models can be quite heavy on memory consumption because the models (neural networks) are relatively large. The size of these models is currently diverging into two directions:
- New methods of training neural networks may result in smaller, more efficient models. Some up-to-date examples are given in this article by Deci, a provider of open-source AI models. The article lists some of Deci’s own models, but also various other, commonly cited models from third-party sources.
- On the other hand, ever larger and larger models (with more and more pre-learned training data) may produce ever more accurate results and surprising, emergent capabilities. The most known example is GPT-4 which is assumed to be one of the largest models in the world, although its actual size has never been disclosed by OpenAI.
A practical example that sits somewhere in the middle is Stable Diffusion, an image-generating AI. Its most basic version requires a minimum of 6 GB of video memory to run, but more advanced versions like Stable Diffusion 1.5 or SDXL 1.0 would rather recommend up to 32 GB of video memory. This assumes you are running the software on a dedicated GPUs such as NVIDIA GeForce or AMD Radeon with dedicated video memory.
Aside from the model itself, memory consumption also depends on the desired output resolution of the created image.
Comparison of GPUs and NPUs
While it’s evident that dedicated GPUs offer impressive TOPS (trillion operations per second), their limited amount of video memory may become a bottleneck when dealing with extensive AI models. This is especially true for mid-range graphics cards such as NVIDIA GeForce RTX 4070 Laptop GPU, which only has a maximum of 8 GB GDDR6. The specs of these kind of consumer-focused graphics cards are optimised for 3D rendering and gaming, not primarily for AI.
This limitation is particularly noticeable when you envision to run AI models within gaming scenarios, where the GPU’s video memory is already heavily utilised for game assets. The challenge here is that while buffering from video memory (VRAM) to system memory (DRAM) is technically feasible, it would encounter its next bottleneck at the GPU’s PCIe interface, making memory swapping generally undesirable for AI.
In contrast, NPUs integrated within CPUs have direct access to the system’s DRAM, which is not only typically larger than the VRAM on GPUs but also – in most laptops – upgradeable. While DRAM itself might be slower than VRAM in terms of access latency, the interface between CPU and DRAM is typically wider (and less occupied) in terms of bandwidth than between a dGPU and its PCIe bus. This allows NPUs to leverage the full capacity of system memory, avoiding memory swapping and bottlenecks.
Conclusion: when evaluating AI acceleration capabilities, one must consider not just the raw TOPS figures but also the amount of available memory. For smaller, more narrowly defined inferencing tasks with a high or unpredictable variety of memory demands, NPUs might be the more suitable option, thanks to their unlimited use of system memory and avoidance of bottlenecks. Conversely, dedicated GPUs remain the better choice for heavy computational tasks such as image generation or model training, particularly when the user is aware of and can work within the given VRAM capacity of the available GPU.
Further reading
Meanwhile, here are a few relevant articles and discussions to dig deeper into this topic. If you have recommendations for other deep dive articles, podcast episodes or talks that might be relevant to this list, please share in the comments below.
1) “Broken Silicon” podcast episode with game AI developer
Episode #235: “PlayStation 6 AI, Nvidia, AMD Hawk Point, Intel Meteor Lake”, can be listened to on Apple Podcasts, Spotify, YouTube and Soundcloud
Related timestamps:
- 11:31 The Next 2D – 3D Moment for Gaming could be Neural Engine AI
- 20:44 AMD Hawk Point and the Importance of TOPs in APUs
- 27:30 Intel Meteor Lake’s NPU – Does it matter if it’s weaker than AMD?
- 33:03 AMD vs Qualcomm Snapdragon Elite X
- 40:45 Intel’s AVX-512 & NPU Adoption Problem with AI…
- 53:01 Predicting how soon we’ll get Next Gen AI in Games
- 1:27:19 AMD’s Advancing AI Event & ROCm, Nvidia’s AI Advantage
- 1:50:20 Intel AI – Are they behind? Will RDNA 4 be big for AI?
2) Performance testing
List of articles:
- I tested Meteor Lake CPUs on Intel’s optimized AI tools: AMD’s chips often beat them [Tom’s Hardware]
- (more coming soon)
Your feedback
Thank you for taking the time to read our article on AI acceleration in laptops. We will keep the lists and tables in this article up to date. For corrections, current suggestions or if you have any questions about AI acceleration in our systems, please write us a comment on Reddit or check out the #ai-discussion channel on our Discord server. Thank you very much for your feedback!