
























































































KI-Beschleunigung in Laptops bezeichnet die Ausführung von KI-Algorithmen direkt auf der Hardware (anstatt in der Cloud). Wir möchten in diesem Artikel einen Überblick über die Grundlagen und zukünftigen Möglichkeiten geben und aufzeigen, in welchen XMG- und SCHENKER-Laptops die beschleunigte Ausführung von KI bereits möglich ist. Der Artikel konzentriert sich ausschließlich mit den technischen Aspekten der KI-Beschleunigung.
Einführung
Künstliche Intelligenz in Form von Large Language Models (LLMs) und Diffusionsmodellen hat zuletzt mit weit verbreiteten Diensten wie Dall-E, Stable Diffusion, Midjourney und ChatGPT Einzug in den Mainstream gehalten. Die sich bereits über Jahre ankündigende Entwicklung hat die Chip-Hersteller dazu veranlasst, Teile ihrer Hardware-Designs zu optimieren, um KI-Algorithmen schneller und mit geringerem Stromverbrauch auszuführen. Dieser Beitrag gibt einen Überblick über den aktuellen Stand dieses Ökosystems und darüber, welche XMG & SCHENKER Laptops bereits über KI-Beschleunigung verfügen.
Welche Hardware brauche ich, um für KI-Anwendungen gerüstet zu sein?
Im folgenden FAQ-Beitrag zeigen wir, welche Hardware für KI-Anwendungen nötig ist:
Was ist der Unterschied zwischen Cloud-basierter und lokal ausgeführter KI?
Derzeit werden praktisch alle KI-Anwendungen, die auf Privatanwender und Produktivität ausgerichtet sind, wie z.B. ChatGPT, in der Cloud betrieben. Wenn ein Nutzer eine Anfrage an ChatGPT stellt, wird die Antwort auf den Servern von OpenAI generiert und nicht auf dem lokalen Rechner des Nutzers.
Es gibt jedoch schon heute bemerkenswerte Ausnahmen von diesem Cloud-zentrierten Ansatz. Softwarepakete wie Stable Diffusion und GPT4All („GPT für alle“) markieren eine Verlagerung hin zur lokalen KI-Ausführung in Laptops. Diese Open-Source-Modelle werden direkt auf dem Computer des Nutzers installiert und ausgeführt. Ursprünglich waren für die lokale Ausführung dieser Modelle leistungsstarke Grafikprozessoren mit großem Grafikspeicher erforderlich. Neuere und künftige CPU-Plattformen mit eingebauten KI-Beschleunigern, den sogenannten „NPUs“ (Neural Processing Units), stellen die Möglichkeit zur lokalen Ausführung nun auf eine breitere, kostengünstigere Basis.
Welche Vorteile bringt es, KI lokal statt in der Cloud auszuführen?
Es ist zu erwarten, dass lokale KI-Beschleuniger zunehmend enger definierte und praxisorientierte Anwendungsfälle ermöglichen. Ob es darum geht, Inhalte zu generieren, bestehende Arbeitsabläufe zu erweitern oder das Nutzererlebnis zu verbessern – die Ausführung dieser Aufgaben auf lokaler Hardware bietet mehrere Vorteile:
- Geringere Latenzzeit: Durch die lokale Ausführung entfallen die Verzögerungen, die bei der Client-Server-Kommunikation auftreten, wodurch schnellere Antworten möglich sind. Dies ermöglicht ggf. Echtzeit-Anwendungen, die eine sofortige Reaktion erfordern, wie z.B. Videokonferenzen, Musikproduktion und Gaming.
- Unabhängigkeit von der Internetverbindung: Die Ausführung ist weniger abhängig von der Qualität der Internetverbindung des Anwenders.
- Skalierbarkeit für Entwickler: Durch die Nutzung lokaler Hardware können Entwickler ihre Anwendungen skalieren, ohne eine umfangreiche Serverinfrastruktur betreiben zu müssen. Damit sinken die finanziellen Hürden und Ausfallrisiken, was insbesondere kleineren, unabhängigen oder gemeinnützigen Entwicklern zugutekommt.
- Sicherheit und Datenschutz: Die lokale Ausführung von KI-Algorithmen erhöht die Sicherheit, da die Notwendigkeit, potenziell sensible Daten an Drittanbieter-Server zu übertragen, vermieden wird. Dienste wie ChatGPT speichern derzeit sämtliche Eingaben etwa zum Zwecke des Trainings zukünftiger Modelle. Damit ist das Hochladen von persönlichen oder vertraulichen Daten ein erhebliches Datenschutzrisiko. Lokale KI-Modelle lösen dieses Problem, indem die Daten idealerweise vollständig beim Anwender verbleiben.
Zukünftige Anwendungsfälle für lokale KI könnten sein:
- Benutzeroberflächen: Lokale KI könnte intuitivere und reaktionsschnellere Elemente wie fortschrittliche Spracherkennung und Sprachübersetzung in Echtzeit ermöglichen oder die Konfiguration der Benutzeroberfläche an die Präferenzen der Benutzer anpassen.
- Spiele: Verbesserter Realismus in Spielen durch KI, z. B. durch lernfähige KI-Gegner oder natürliche, sprachliche Interaktion mit NPCs (Nicht-Spieler-Charakteren) in RPGs, Adventures oder Simulationen.
- Generative KI und persönliche Assistenten: Universelle Chatbots und Tools zur Bilderstellung gibt es bereits, aber sie könnten eine breitere Anwendung finden, sobald sie ohne die bei Online-Abonnements bestehenden Datenschutz-Bedenken lokal genutzt werden können.
KI-Beschleunig in Laptops: NPUs, GPUs, Tensor Cores usw.
KI oder LLMs könnten prinzipiell auf jeder CPU (Central Processing Unit) ausgeführt werden. Aber wie beim 3D-Rendering ist die Ausführung auf den CPU-Kernen sehr langsam, selbst wenn der Prozessor mit maximaler Leistung betrieben wird.
Es gibt eine Reihe spezialisierter Hardware-Designs, die die gleiche Aufgabe viel schneller und effizienter erledigen können.
Die Effizienz wird in „Leistung pro Watt“ definiert, d.h. wie viel elektrische Energie ein System benötigt, um eine bestimmte Aufgabe zu erfüllen. Bei mobiler Hardware wie Handys und Laptops führt eine höhere Effizienz direkt zu einer längeren Akkulaufzeit.
Wir haben hier eine Liste mit den gängigsten Beschleunigern zusammengestellt:
| Begriff | Ausbuchstabiert | Beschreibung |
| GNA | Gaussian & Neural Accelerator | GNA ist seit der Intel Core-CPUs der 10. Generation verfügbar,ist auf Audio- und Videoverarbeitung spezialisiert und wurde hauptsächlich für die aktive Geräuschunterdrückung von Webcam- und Mikrofonsignalen verwendet. |
| NPU, VPU, IPU | Neural / Versatile / Intelligent Processor Unit | Dies sind moderne, dedizierte KI-Beschleunigungseinheiten, die in moderne und Next-Gen-CPU-Plattformen eingebaut sind. Im Gegensatz zu Intel GNA sind diese Einheiten eher allgemein auf KI-Modelle (Transformer-Modelle usw.) ausgerichtet und nicht nur speziell für die Audio-/Videoverbesserung konzipiert. Verschiedene Anbieter verwenden derzeit unterschiedliche Akronyme. Im Rahmen dieses Artikels werden sie unter dem Begriff „NPU“ zusammengefasst. |
| GPU | Graphics Processing Units (Grafikkarten) | Grafikkarten wurden ursprünglich für die Beschleunigung von 3D-Grafiken entwickelt, sind aber auch sehr gut für die Beschleunigung von KI geeignet. Sie sind zwar nicht ganz so effizient wie NPUs, aber sie sind extrem leistungsfähig, allgegenwärtig (in großer Zahl und überall verfügbar) und haben eine lange Entwicklungsgeschichte, die zu sehr ausgereiften Designs und stabilen Treibern und Entwicklungs-Tools geführt hat. GPUs gibt es als iGPU (in CPUs integriert) und dGPU (dediziert, eigenständig). NVIDIA-GPUs sind bei KI-Entwicklern aufgrund ihrer gut dokumentierten CUDA-Programmierschnittstelle besonders verbreitet. |
| – | Tensor Cores | Tensor Cores sind ein Teilbereich des GPU-Hardwaredesigns, der von NVIDIA erstmals 2019 eingeführt wurde. Sie wurden entwickelt, um KI-Workloads zu beschleunigen. Auf der Client-Seite werden sie für Spiele (Upscaling, Frame-Generierung) und auf der Server-Seite (in Rechenzentren) für das Training und die Ausführung größerer KI-Modelle verwendet, die Dienste wie ChatGPT unterstützen. Im Grunde genommen sind Tensor Cores wie NPUs – da sie aber nur in dedizierten GPUs (dGPUs) verfügbar sind, werden sie hier als separat aufgeführt. Bei Laptops ist es in der wünschenswert, wenn man die Nutzung der dGPU für kleine, wiederkehrende, tägliche Arbeitslasten vermeidet, da das Aufwachen der dGPU und deren Energieaufnahme mit einer Reduktion der Akkulaufzeit einhergeht. |
| TPU | Tensor Processing Units | Eine besondere Art von NPU, die von Google entwickelt wurde. TPUs haben ihren eigenen Speicher direkt auf dem Chip, während NPUs noch der traditionellen „von Neumann“-Architektur folgen, bei der Recheneinheiten und Speicher getrennt sind. TPUs gelten als stromsparender als NPUs, haben aber eine geringere Spitzenleistung. TPUs sind derzeit nur in der Cloud-Architektur von Google und in einigen neueren Google-Smartphones verfügbar. |
| AVX512 | Advanced Vector Extensions (512-bit) | AVX512 ist eine Erweiterung der x86-CPU-Architektur und in einigen, aber nicht allen modernen CPUs verfügbar. Die Nutzung von AVX512 zur KI-Beschleunigung ist weniger effizient als NPUs und GPUs, aber deutlich effizienter als die normalen x86-CPU-Kerne. Sie können in Systemen, in denen keine NPUs oder GPUs verfügbar sind, als Ausweichlösung dienen. |
Weitere Informationen über die technologische Geschichte vom KI-Beschleunigung befinden sich in diesem Wikipedia-Artikel auf englisch: AI accelerator.
Fazit: Für Consumer-Hardware sind NPUs, die in der CPU untergebracht sind, offenbar die flexibelste Lösung und gleichzeitig sehr energieeffizient. Ein Beispiel für die Flexibilität ist die Tatsache, dass NPUs vom Ausbau des System-Arbeitsspeichers profitieren (sie können größere Datenmengen verarbeiten), während TPUs auf ihren eigenen, integrierten Speicher beschränkt sind. Damit sind NPUs den iGPUs sehr ähnlich, die ebenfalls von schnellerem, größerem RAM profitieren. Die Möglichkeit, von der KI-Beschleunigung zu profitieren, ohne eine leistungsstarke (teure, energiehungrige) Grafikkarte zu benötigen, wird die Ausführung von lokaler KI auf einer breiteren Palette von portablen Geräten praktikabel machen.
Integrierte NPUs könnten in zukünftigen CPU-Plattformen zur Norm werden
NPUs kommen bereits in aktueller Consumer-Hardware zum Einsatz:
- Die AMD Ryzen 7040-Serie (Codename „Phoenix“) enthält eine NPU von AMD, die unter dem Begriff „Ryzen AI“ vermarktet wird.
- Die Intel Core Ultra-Serie (Codename „Meteor Lake“) enthält eine NPU von Intel, die eine leistungsfähige Steigerung gegenüber dem vorherigen „GNA“ (Gaussian & Neural Accelerator) darstellt, der seit der 10. Generation (Ice Lake) Teil der Intel Core-Plattform ist.
- AMD hat bereits die AMD Ryzen 8040-Serie (Codename „Hawk Point“) angekündigt, die die Leistung der NPU, die mit „Phoenix“ eingeführt wurde, steigern soll.
Diese Produktsegmente zielen vornehmlich auf den mobilen Bereich ab. Bei Notebooks bzw. Laptops sind Faktoren wie Energieeffizienz und Akkulaufzeit für das Nutzererlebnis bekanntlich entscheidend. Diese mobilen CPU-Plattformen werden zeitversetzt oftmals auch in Mini-PCs und anderen „Thin Client“-Lösungen angeboten.
Desktop-Plattformen wurden bisher noch nicht mit NPUs angekündigt – aber das ist vielleicht nur eine Frage der Zeit. Derzeit werden Desktop-CPUs in High-End-PCs in der Regel mit einem leistungsstarken, dedizierten Grafikprozessor gepaart, so dass es bereits reichlich KI-fähige Hardware in Desktops gibt.
NPU in AMD Ryzen 7040-CPUs(AMD Ryzen AI)
Einführung in Ryzen AI
AMD hat mit der Einführung der AMD Ryzen 7040-Serie begonnen, den Begriff „Ryzen AI“ zu verwenden. Er beschreibt nicht nur die NPU, die sich in der CPU befindet, sondern auch eine Reihe von Entwicklungs-Tools, Treibern und Softwareanwendungen, die mit ihr einhergehen. In den Fußnoten auf der Ryzen AI-Website heißt es:
„Ryzen AI ist definiert als eine Kombination aus dedizierter KI-Engine, AMD Radeon Grafik-Engine und Ryzen Prozessorkernen, die KI-Funktionen ermöglichen.“
Diese Aussage spielt darauf an, dass AMD bei der Beschleunigung von KI-Workloads sowohl die NPU als auch die iGPU einsetzen kann. In der Fußnote heißt es weiter:
„Eine Aktivierung durch den Erstausrüster und Softwarehersteller ist erforderlich.“ Im Englischen Original: „OEM and ISV enablement is required.“
„Erstausrüster“ ist die Übersetzung von OEM – Original Equipment Manufacturer, also dem Hersteller bzw. Inverkehrbringer des Computers. Das Wort „enablement“ geht eventuell ein bisschen weiter als eine bloße „Aktivierung“:
- „OEM enablement“ beschreibt, dass AMD Ryzen AI möglicherweise nicht auf jedem System mit AMD Ryzen 7040 verfügbar ist. Stattdessen muss der OEM die Funktionalität „bereitstellen“. AMD stellt nicht klar, was genau dieses Enablement beinhaltet.
- „ISV Enablement“: ISV steht für „Integrated Software Vendor“. Diese Aussage beschreibt wahrscheinlich das Offensichtliche: Softwareentwickler müssen entsprechende APIs verwenden, um ihre KI-Arbeitslasten auf die NPU oder iGPU zu verlagern. Vorhandene Software wird nicht einfach auf magische Weise beschleunigt.
Die Anforderung der „OEM-Aktivierung“ hat bei Endkunden mit AMD Ryzen 7040-Systemen bereits für einige Verwirrung gesorgt:
- Wenn man heute ein Ryzen 7040-System kauft, woher weißt man dann, ob Ryzen AI bereits aktiviert ist?
- Wenn ein bestehendes Ryzen 7040-System noch kein Ryzen AI aktiviert hat, ist es dann möglich, dass es später aktiviert wird?
Um diese Fragen zu klären, möchten wir erklären, was genau hinter diesem „OEM enablement“ steckt und wie man herausfinden kann, ob ein System bereits AMD Ryzen AI aktiviert hat.
Hardware und Treiber: Aktivierung der IPU in Ryzen AI
Im Marketing verwendet AMD den Begriff „KI-Engine“, um die KI-Beschleunigung in Laptops bei seiner Ryzen-Plattform zu beschreiben. In den Spezifikationen und Treibern für Entwickler wird der Begriff „IPU“ (Intelligent Processor Unit) verwendet. Der Einheitlichkeit halber werden wir den Begriff „IPU“ in diesem Absatz synonym mit „NPU“ oder „KI-Engine“ verwenden.
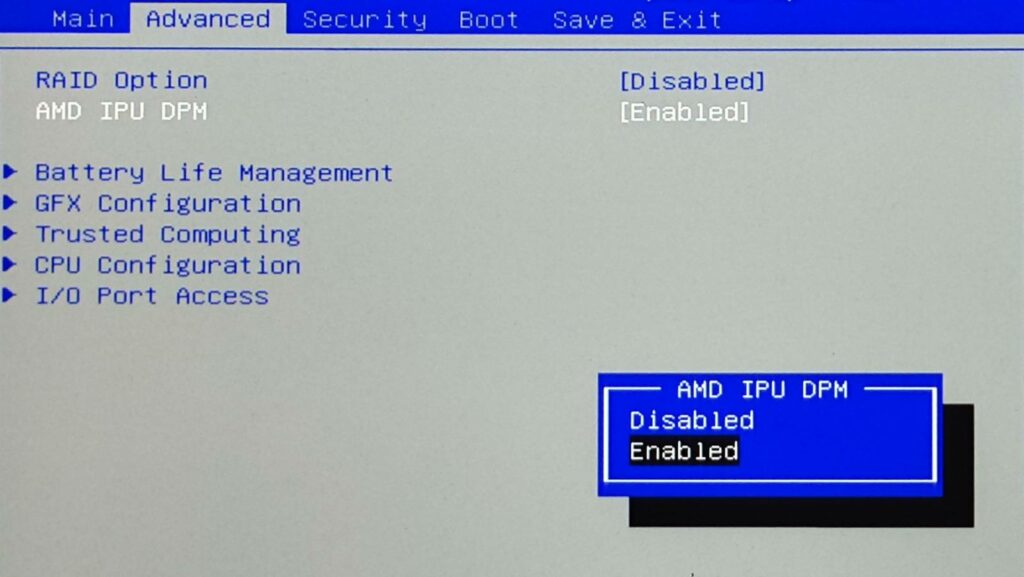
Zuerst muss die IPU im BIOS aktiviert werden. Ob sie aktiviert ist oder nicht, hängt vom jeweiligen Hersteller ab.
Die erforderliche BIOS-Option ist Teil des Referenzcodes von AMD, wird aber nicht unbedingt in allen kompatiblen Systemen für den Endbenutzer angezeigt. Wenn man eine Option für „IPU“ oder „IPU DPM“ im BIOS-Setup findet, kann man sie aktivieren. Sollte keine Option vorhanden sein, kann sie evtl. trotzdem bereits aktiviert sein.
Für XMG- und SCHENKER-Laptops mit Prozessoren aus der AMD Ryzen 7040-Serie und darüber hinaus bieten wir eine Option zur Aktivierung und Deaktivierung der IPU in allen kompatiblen Modellen über eine BIOS-Setup-Option. Die IPU ist dann standardmäßig aktiviert, kann aber nach Belieben deaktiviert werden. Details dazu stehen weiter unten im Abschnitt „Welche XMG- und SCHENKER-Laptops haben die KI-Beschleunigung bereits aktiviert?“.
Sobald sie aktiviert ist, wird die IPU dem Betriebssystem als zusätzliches Gerät zur Verfügung gestellt. Sie befindet sich dann im Windows Geräte-Manager unter „Systemgeräte“ mit der Hardware-ID „VEN_1022&DEV_1502“. Siehe Screenshot:
[Screenshot zum Geräte-Manager wird nachgereicht]
Die IPU ist standardmäßig aktiviert, kann aber nach eigenem Ermessen deaktiviert werden.
Falls dieses Gerät im Geräte-Manager nicht auffindbar ist, dann ist die IPU wahrscheinlich nicht im BIOS aktiviert.
Der Treiber für dieses IPU-Gerät ist Teil des AMD-Grafiktreiberpakets, auch bekannt als „AMD Software: Adrenalin Edition“. Je nach System muss man möglicherweise zuerst den OEM-Grafiktreiber installieren, bevor man den allerneuesten Grafiktreiber von AMD installiert. Die technischen Hintergründe dieser zweistufigen Vorgehensweise werden in diesem Thread ausführlich erläutert:
Integration in das Betriebssystem
Die Integration von AMD Ryzen AI und anderen NPU-beschleunigten KI-Workloads in das Betriebssystem steckt noch in den Kinderschuhen. Der einzige Anwendungsfall, der uns bisher bekannt ist, heißt „Windows Studio Effects“, wie in diesem Artikel beschrieben:
Zu diesen Effekten gehören Standard-Videokonferenzfunktionen wie „Hintergrundunschärfe“ (für die Webcam) und „Sprachfokus“ (schaltet Hintergrundgeräusche am Mikrofon aus), aber auch die neuartige Funktion „Augenkontakt“, die den Webcam-Video-Feed so aussehen lässt, als würde der Nutzer tatsächlich in die Webcam schauen, anstatt auf den Bildschirm darunter.
Es scheint, dass diese Funktionen nur selektiv von Microsoft (hier ISV im Sinne der vorherigen Definition von AMD) den teilnehmenden OEMs zur Verfügung gestellt werden. Neben der NPU scheint „Windows Studio Effects“ bestimmte, von Microsoft validierte Peripherie (Webcams, Mikrofon, Anbindungen) zu benötigen, damit Microsoft die Qualität des Nutzererlebnisses garantieren kann. Da Microsofts Enablement-Prozess derzeit nur für große OEMs konzipiert zu sein scheint, nehmen wir derzeit nicht daran teil. Daher sind die „Windows Studio Effects“ auf XMG- und SCHENKER-Laptops nicht verfügbar, selbst wenn eine NPU vorhanden und aktiviert ist.
Ob zukünftige Integrationen seitens Microsofts ebenfalls einer solch selektiven OEM-Aktivierungsstrategie folgen werden, ist noch unbekannt.
Software-Unterstützung für Entwickler
AMD stellt relevante Informationen für Entwickler auf der eigenen Website und auf github zur Verfügung:
- Ryzen AI Software [amd.com]
- Ryzen AI Software [github]
Zur Erinnerung: Unsere Hardware, Firmware und Treiber sind bereit für die lokale KI-Beschleunigung
Wie oben beschrieben, hängt die KI-Beschleunigung in Laptops von einer vollständigen Pipeline ab, die von der Hardware über die Firmware und den Treiber bis hin zur Software reicht. Einige Softwarehersteller (z. B. Microsoft) sind derzeit noch wählerisch, auf welchen Geräten sie ihre KI-Anwendungen ausrollen. Das könnte sich aber bald ändern, wenn sich NPUs weiter verbreitet haben und mehr Drittentwickler dieses aufkeimende Ökosystem nutzen und Anwendungen entwickeln, die von den NPUs in aktuellen und zukünftigen CPU-Plattformen Gebrauch machen.
Unterstützung für Linux
Offizielle Linux-Treiber für AMD Ryzen AI sind seit Ende Januar 2024 verfügbar. Weitere Details dazu gibt es in diesem Beitrag.“
NPU in der Intel Core Ultra-Serie (Intel AI Boost)
Intel hat im Dezember 2023 die neue Intel Core Ultra-Serie auf den Markt gebracht. Mit dieser Generation integriert Intel eine leistungsstarke NPU in die CPU-Plattform, Seite an Seite mit einer ebenfalls sehr starken iGPU. Während frühere Intel Core i-Generationen nur über den älteren „GNA“ (Gaussian & Neural Accelerator) verfügten, wird die neue Intel Core Ultra-Serie sowohl über eine NPU als auch über die den älteren GNA integrieren. Intel stellt entsprechende Treiber sowohl für Windows als auch für Linux bereit.
Offizielle Dokumentationen befinden sich hier:
- Intel Core Ultra Prozessorenreihe [intel.com]
- Der KI-PC – powered by Intel [intel.com]
- Intel NPU-Treiber – Release Notes [intel.com]
Intel spricht derzeit von „mehr als 300 KI-beschleunigten ISV-Funktionen“. Das beschreibt also von Drittanbietern implementierte Lösungen, von denen viele derzeit noch mit Content Creation zusammenhängen. Das sind nicht 300 verschiedene Programme, sondern die einzelnen Funktionen (z.B. Effekte, Filter) innerhalb diverser Programme. Intel gibt auf der Seite „Der KI-PC“ einige Beispiele.
Unsere Enablement-Strategie für KI in der Intel Core Ultra-Serie
Unser Enablement für die NPU in Meteor Lake wird ähnlich sein wie das von AMD:
- Wir werden die Option zur Aktivierung der NPU über das BIOS-Setup freischalten.
- Die Option ist standardmäßig aktiviert.
- Der NPU-Treiber wird von uns zur Verfügung gestellt.
- Das Gerät wird im Gerätemanager als „Intel AI Boost“ gekennzeichnet.
Es wird dann von Softwareanbietern abhängen, ob sie die NPU für ihre Nutzererfahrungen nutzen wollen oder nicht.
Wir gehen davon aus, dass wir Laptops mit Meteor Lake im zweiten Quartal 2024 auf den Markt bringen werden (siehe Roadmap-Update). Davor werden wir versuchen, die „Windows Studio Effects“-Freigabe bei Microsoft zu beantragen. Allerdings ist derzeit nicht bekannt, ob dieser Antrag erfolgreich sein wird. Unabhängig von Microsofts OS-Integration wird die NPU in der Intel Core Ultra-Serie für Softwareentwickler und Drittanbieter-Apps in XMG- und SCHENKER-Laptops verfügbar sein.
Welche XMG- und SCHENKER-Laptops haben bereits NPUs in ihre CPU-Plattformen eingebaut?
Zunächst müssen wir noch einmal daran erinnern, dass jeder Laptop mit einer NVIDIA GeForce RTX oder einer anderen modernen, dedizierten Grafikkarte sehr gut in der Lage ist, KI-Workloads lokal auszuführen. Die Komplexität dieser Workloads wird nur durch die Größe des Grafikspeichers (VRAM) und die Wahl des KI-Modells begrenzt. Dieser Artikel konzentriert sich jedoch mehr auf die kleineren, energieeffizienteren NPU-Komponenten, die direkt in aktuelle und zukünftige CPUs integriert sind.
Gemeinsam mit unseren ODM-Partnern haben wir BIOS-Updates entwickelt, mit denen Endnutzer die NPU-Komponente in ihrer CPU-Plattform aktivieren und deaktivieren können. Derzeit gilt dies für die folgenden Modelle:
| Serie | CPU-Plattform | Status |
| SCHENKER VIA 14 Pro | AMD Ryzen 7040-Serie | Veröffentlicht |
| XMG APEX (L23) | AMD Ryzen 7040-Serie | Veröffentlicht |
| XMG CORE (L23) | AMD Ryzen 7040-Serie | Veröffentlicht |
Hinweise:
- Modelle, die nicht in dieser Liste aufgeführt sind, haben keine NPU-Komponenten in ihrer CPU-Plattform.
- Die Nutzung von CPU, iGPU, dGPU oder AVX512 (falls verfügbar) für die lokale KI-Verarbeitung ist unabhängig von der NPU-Fähigkeit. Mit anderen Worten: Laptop-Modelle ohne NPU können trotzdem KI-Workloads verarbeiten – sie müssen nur andere Komponenten zur Beschleunigung verwenden.
Vergleich der KI-Rechenleistung
Wir möchten einen markenunabhängigen Leistungsvergleich zwischen den KI-Beschleunigungsfähigkeiten aktueller CPU-Plattformen durchführen. Für den Anfang verwenden wir die Metrik „TOPS“ (TeraOPS, verstanden als „Billionen Operationen pro Sekunde“) als Leistungsindikator für die KI-Beschleunigung in Laptops. Später werden wir evtl. auch branchenübliche Benchmark-Ergebnisse hinzufügen.
Eine Vorschau befindet sich hinter diesem Link:
- CPU Platform AI Acceleration Comparison [Google Sheets]
Die Tabelle ist noch in Arbeit. Die Daten basieren derzeit auf öffentlich zugänglichen Angaben (Spezifikationen von CPU-Anbietern und Marketingmaterialien) und nicht auf unseren eigenen Tests. Deshalb sind viele Bereiche (z. B. der iGPU-Vergleich in der KI) noch offen.
Grundsätzlich gilt:
- Wenn eine iGPU bei Spielen oder 3D-Renderings stärker ist (als eine andere iGPU), ist sie wahrscheinlich auch bei KI stärker.
- Eine gute dGPU wird immer mehr Leistung haben als eine in die CPU integrierte NPU. Die begrenzte Speicherkapazität von dGPUs kann jedoch ein Problem darstellen. Mehr dazu im nächsten Abschnitt.
Wie viel Speicher brauche ich für lokale KI-Beschleunigung in Laptops? Und wie wirkt sich das auf meine Wahl zwischen NPU und GPU aus?
Vorläufige Antwort
Wir würden folgende Empfehlung aussprechen: Ein zukunftssicheres System, das für lokale KI-Workloads ausgelegt ist, sollte mindestens 32 GB Arbeitsspeicher haben.
Um diese Empfehlung in einen Kontext zu setzen, möchten wir die Unterschiede zwischen NPUs und GPUs in Bezug auf Speicherkapazität und -zugriff näher erläutern.
Größe der aktuellen und zukünftigen KI-Modelle
Beim Vergleich der reinen Leistung (gemessen in TOPS) von KI-Beschleunigern muss man auch den Speicherbedarf von realen KI-Anwendungen berücksichtigen.
KI-Modelle können ziemlich viel Speicherplatz beanspruchen, weil die Modelle (neuronale Netze) relativ groß sind. Die Größe dieser Modelle divergiert derzeit in zwei Richtungen:
- Neue Methoden zum Training neuronaler Netze können zu kleineren, effizienteren Modellen führen. Einige aktuelle Beispiele werden in diesem Artikel von Deci, einem Anbieter von Open-Source-KI-Modellen, vorgestellt. Der Artikel listet einige der eigenen Modelle von Deci auf, aber auch verschiedene andere, in der Community renommierte Modelle anderer Anbieter.
- Andererseits können immer größer werdende Modelle (mit immer mehr vorgelernten Trainingsdaten) ggf. immer imposantere Ergebnisse oder überraschende, neue Fähigkeiten hervorbringen. Das bekannteste Beispiel ist GPT-4, von dem angenommen wird, dass es eines der größten Modelle der Welt ist (seine tatsächliche Größe wurden von OpenAI bisher nicht bekannt gegeben).
Ein praktisches Beispiel, das ungefähr in der Mitte angesiedelt ist, ist Stable Diffusion, eine KI zur Bilderzeugung. Ihre einfachste Version benötigt mindestens 6 GB, aber fortgeschrittene Versionen wie Stable Diffusion 1.5 oder SDXL 1.0 empfehlen bis zu 32 GB Grafikspeicher. Diese Empfehlung geht davon aus, dass man die Software auf einer dedizierten Grafikkarte (NVIDIA GeForce oder AMD Radeon) mit eigenem Grafikspeicher ausführt.
Der Speicherverbrauch hängt nicht nur vom Modell selbst ab, sondern auch von der gewünschten Auflösung des mit Stable Diffusion erzeugten Bildes.
Vergleich von GPUs und NPUs
Es ist zwar klar, dass dedizierte GPUs beeindruckende TOPS-Werte (Billionen Operationen pro Sekunde) bieten, aber ihr begrenzter Grafikspeicher kann bei umfangreichen KI-Modellen zu einem Engpass werden. Das gilt besonders für Mittelklasse-Grafikkarten wie die NVIDIA GeForce RTX 4070 Laptop-GPU, die nur maximal 8 GB GDDR6 hat. Die Ausstattung dieser für Endverbraucher konzipierten Grafikkarten sind in erster Linie für 3D-Rendering und Gaming optimiert, nicht primär für KI.
Diese Einschränkung macht sich vor allem dann bemerkbar, wenn man KI-Modelle direkt im Gaming einsetzen möchte, wo dann der Grafikspeicher ohnehin bereits von den Spielinhalten belegt ist. Die Herausforderung besteht darin, dass die Pufferung (Swapping) vom Grafikspeicher (VRAM) in den Systemspeicher (DRAM) zwar technisch machbar ist, aber an der PCIe-Schnittstelle dann auf den nächsten Engpass stößt. Memory-Swapping ist daher für KI generell unerwünscht und ließe die Performance zu sehr einbrechen.
Im Gegensatz dazu haben NPUs, die in CPUs integriert sind, direkten Zugriff auf den DRAM des Systems, der nicht nur in der Regel größer ist als der VRAM von GPUs, sondern auch – in den meisten Laptops – aufrüstbar ist. Der DRAM selbst ist zwar langsamer als der VRAM, was die Zugriffslatenz angeht, aber die Schnittstelle zwischen CPU und DRAM hat in der Regel eine größere (und weniger belegte) Bandbreite als die zwischen einer Grafikkarte und ihrer PCI-Express-Schnittstelle. Dadurch können NPUs die volle Kapazität des Systemspeichers ausnutzen und Speicherauslagerungen und Engpässe vermeiden.
Fazit: Bei der Betrachtung von KI-Beschleunigung darf man nicht nur die reinen TOPS-Werte vergleichen, sondern muss auch die Menge des verfügbaren Speichers berücksichtigen. Für kleinere, enger definierte Inferencing-Aufgaben mit einer hohen oder unvorhersehbaren Menge an Speicherverbrauch sind NPUs dank ihrer großzügigen Nutzung des Systemspeichers und der Vermeidung von Engpässen möglicherweise die geeignetere Option. Umgekehrt sind dedizierte Grafikkarten (dGPUs) nach wie vor die bessere Wahl für schwere Rechenaufgaben wie die Bilderzeugung oder das Modelltraining, vor allem, wenn der Nutzer die VRAM-Kapazität der verfügbaren GPU kennt und innerhalb dieses Limits arbeiten kann.
Links zu weiteren Informationen
Wir sammeln hier ein paar relevante Artikel und Diskussionen, um dieses Thema zu vertiefen. Wenn ihr weitere Artikel, Podcast-Episoden oder Vorträge empfehlen möchtet, die für diese Liste relevant sein könnten, schreibt uns bitte einen Hinweis (Kontakt siehe unten).
1) „Broken Silicon“-Podcast-Episode mit Spiele-KI-Entwickler
Episode #235: „PlayStation 6 AI, Nvidia, AMD Hawk Point, Intel Meteor Lake“, kann auf Apple Podcasts, Spotify, YouTube und Soundcloud angehört werden.
Relevante Zeitstempel:
- 11:31 The Next 2D – 3D Moment for Gaming could be Neural Engine AI
- 20:44 AMD Hawk Point and the Importance of TOPs in APUs
- 27:30 Intel Meteor Lake’s NPU – Does it matter if it’s weaker than AMD?
- 33:03 AMD vs Qualcomm Snapdragon Elite X
- 40:45 Intel’s AVX-512 & NPU Adoption Problem with AI…
- 53:01 Predicting how soon we’ll get Next Gen AI in Games
- 1:27:19 AMD’s Advancing AI Event & ROCm, Nvidia’s AI Advantage
- 1:50:20 Intel AI – Are they behind? Will RDNA 4 be big for AI?
2) Performance-Tests
Liste der Artikel:
- I tested Meteor Lake CPUs on Intel’s optimized AI tools: AMD’s chips often beat them [Tom’s Hardware]
- (mehr demnächst)
Euer Feedback
Vielen Dank, dass ihr euch die Zeit genommen hast, unseren Artikel zur KI-Beschleunigung in Laptops zu lesen. Wir werden die Listen und Tabellen in diesem Artikel fortlaufend aktuell halten. Für Korrekturen, aktuelle Vorschläge oder falls ihr Fragen zur KI-Beschleunigung in unseren Systemen habt, schreibt uns bitte einen Kommentar auf Reddit oder schaut im Kanal #ai-discussion auf unserem Discord-Server vorbei. Vielen Dank für euer Feedback!
